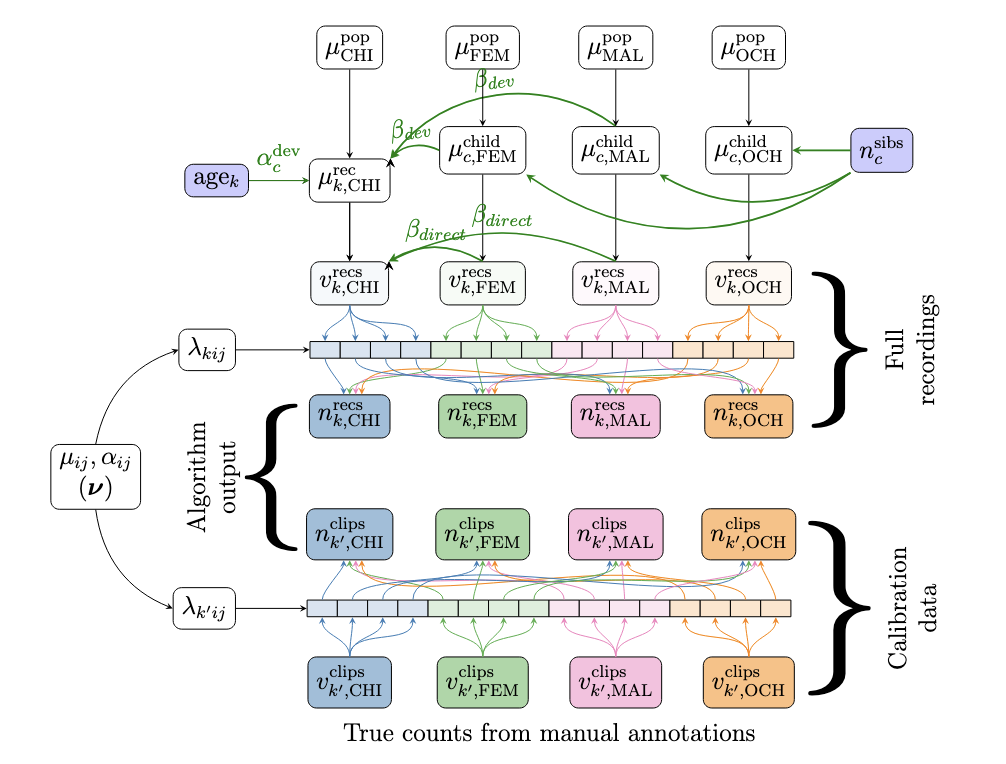
Long-form audio recordings are increasingly used to study individual variation, group differences, and many other topics in theoretical and applied fields of developmental science, particularly for the description of children’s language input (typically speech from adults) and children’s language output (ranging from babble to sentences). The proprietary LENA software has been available for over a decade, and with it, users have come to rely on derived metrics like adult word count (AWC) and child vocalization counts (CVC), which have also more recently been derived using an open-source alternative, the ACLEW pipeline. Yet, there is relatively little work assessing the reliability of long-form metrics in terms of the stability of individual differences across time. Filling this gap, we analyzed eight spoken-language datasets: four from North American English-learning infants, and one each from British English-, French-, American English-Spanish, and Quechua-Spanish-learning infants. The audio data were analyzed using two types of processing software: LENA and the ACLEW open-source pipeline. When all corpora were included, we found relatively low to moderate reliability (across multiple recordings, intraclass correlation coefficient attributed to the child identity (Child ICC), was <50% for most metrics). There were few differences between the two pipelines. Exploratory analyses suggested some differences as a function of child age and corpora. These findings suggest that, while reliability is likely sufficient for various group-level analyses, caution is needed when using either LENA or ACLEW tools to study individual variation. We also encourage improvement of extant tools, specifically targeting accurate measurement of individual variation.
 Jul 2025Language acquisition Machine Learning Statistics
Jul 2025Language acquisition Machine Learning Statistics Jul 2025Collective cognition Inverse problems Statistics
Jul 2025Collective cognition Inverse problems Statistics

 EPJ Data Science, Jan 2025Collective cognition Natural language processing Networks Statistics Inverse problems
EPJ Data Science, Jan 2025Collective cognition Natural language processing Networks Statistics Inverse problems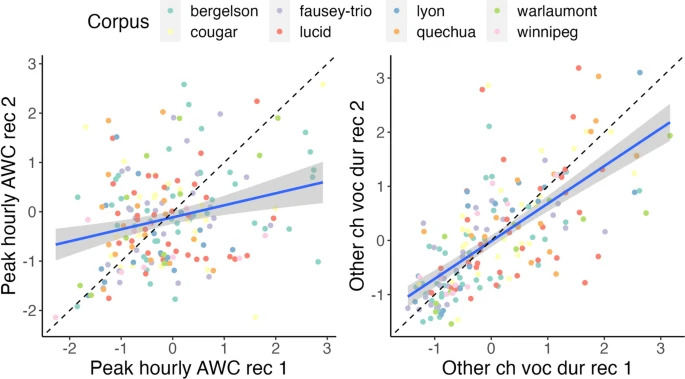 Behavior Research Methods, Sep 2024Language acquisition Statistics
Behavior Research Methods, Sep 2024Language acquisition Statistics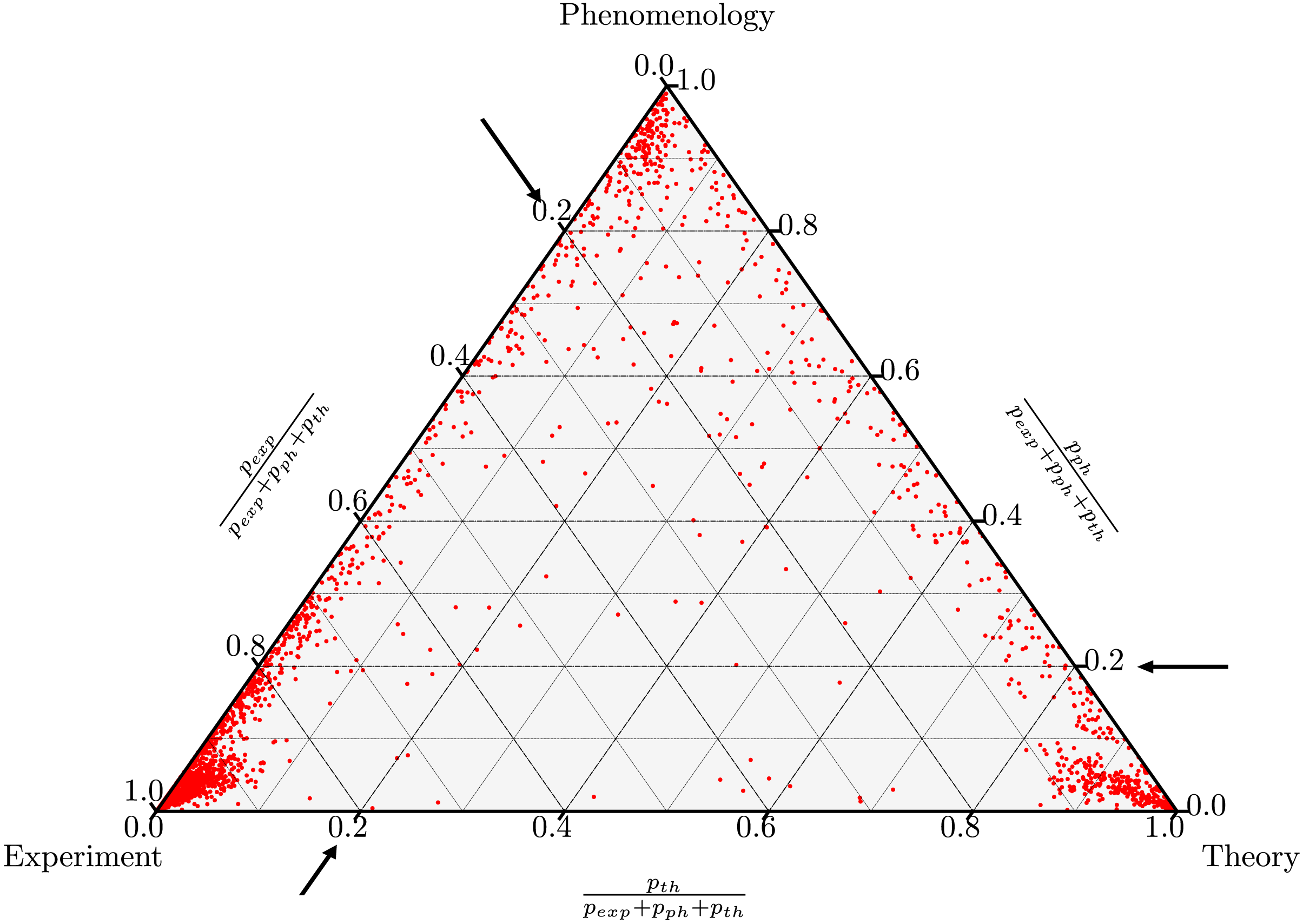 Quantitative Science Studies, Dec 2023Collective cognition Natural language processing Networks
Quantitative Science Studies, Dec 2023Collective cognition Natural language processing Networks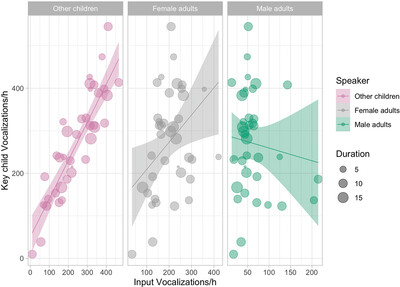 Developmental Science, Feb 2023Language acquisition Statistics
Developmental Science, Feb 2023Language acquisition Statistics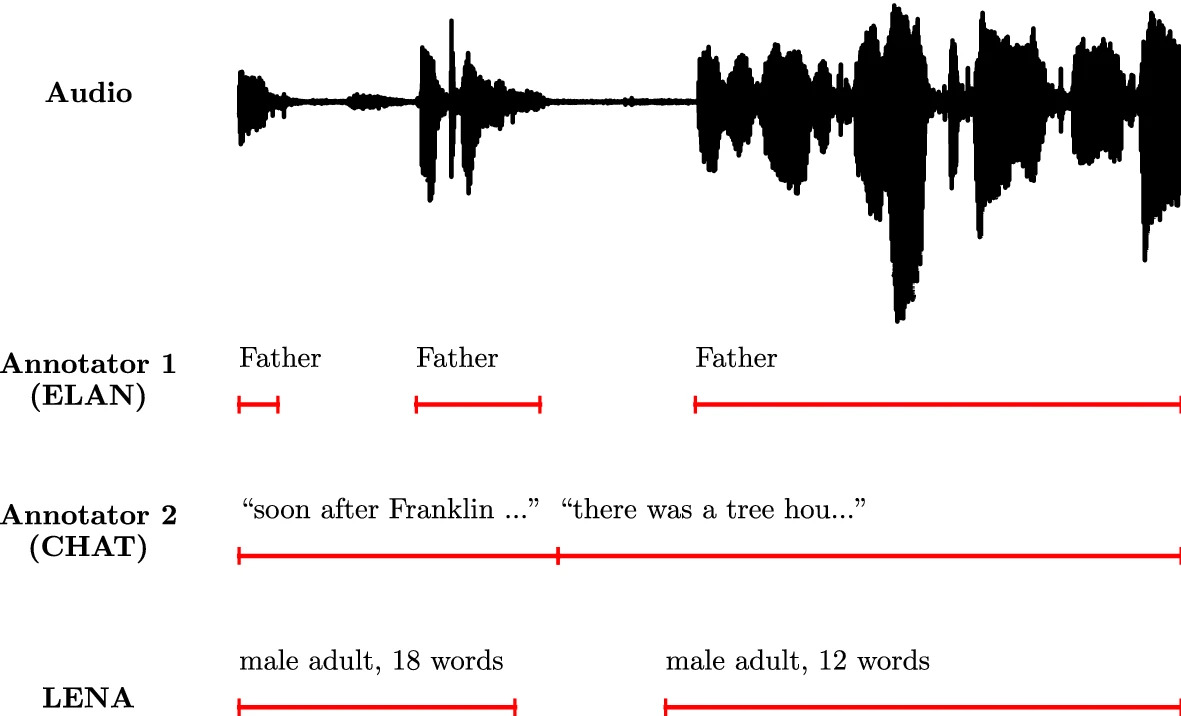 Language Resources and Evaluation, Feb 2022Language acquisition Software
Language Resources and Evaluation, Feb 2022Language acquisition Software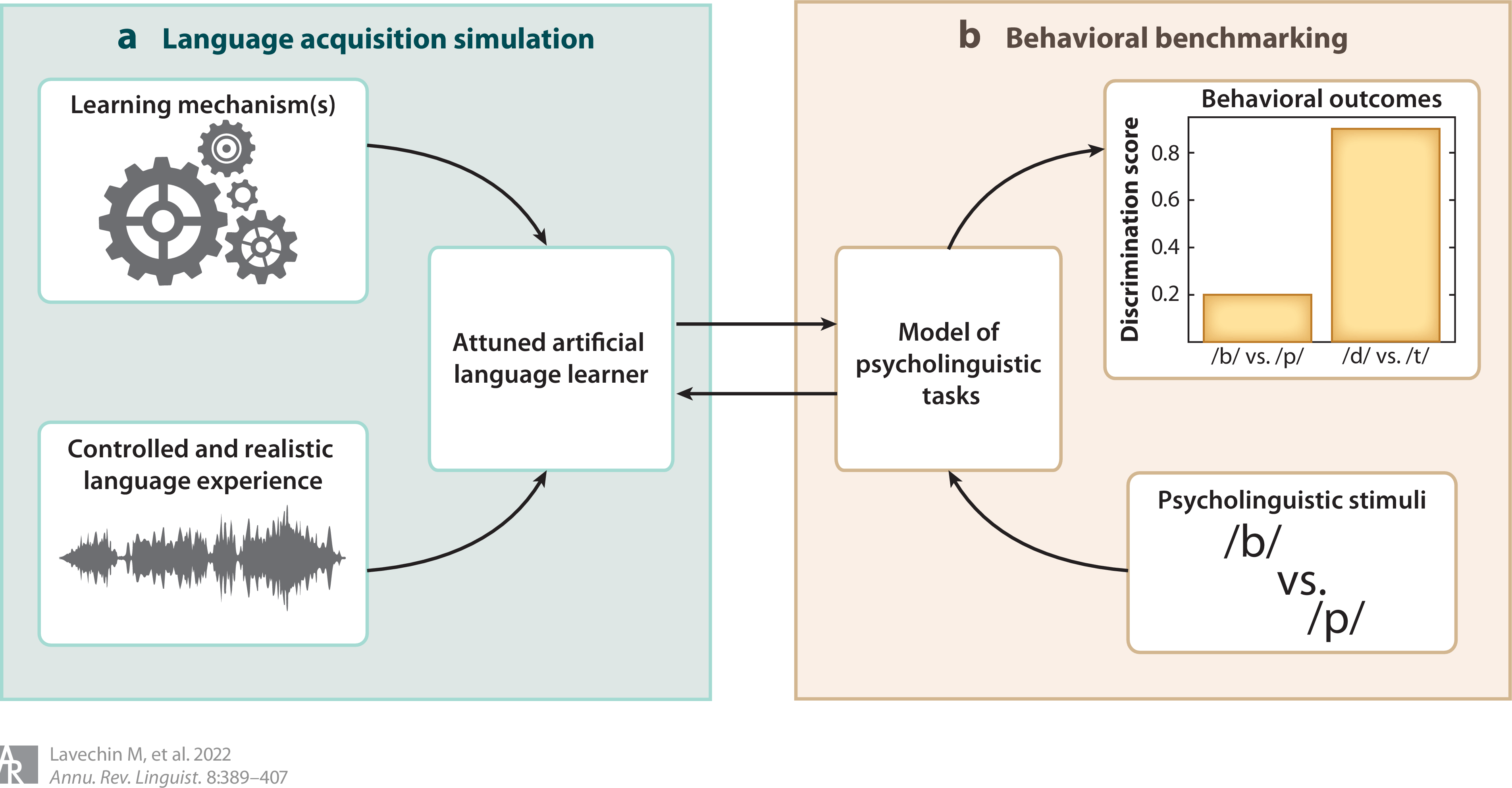 Annual Review of Linguistics, Jan 2022Language acquisition Literature review
Annual Review of Linguistics, Jan 2022Language acquisition Literature review


 Apr 2025Workshop on Large Language Models for the History, Philosophy, and Sociology of Science, TU Berlin
Apr 2025Workshop on Large Language Models for the History, Philosophy, and Sociology of Science, TU Berlin
 Le Média, 2020Epidemics Statistics
Le Média, 2020Epidemics Statistics Le Média, 2019Politics Data mining
Le Média, 2019Politics Data mining

